
Vui lòng đọc hiểu đề trước khi đọc bài viết này tại đây:
https://leetcode.com/problems/top-k-frequent-elements/description/
Table of Contents
1. Cách tiếp cận vấn đề
Bài toán yêu cầu tìm top k phần tử có số lần xuất hiện nhiều nhất, và nó luôn đảm bảo rằng các đáp án sẽ luôn là duy nhất. Một yêu cầu phụ là chúng ta cần giải bài toán tối ưu hơn O(nlogn), đọc tới cái này là mình hiểu nó chặn việc mình sắp xếp theo cách truyền thống (thời gian trung bình là O(nlogn)) và chỉ có thể làm theo hướng sắp xếp sao cho tối ưu nhất là O(n) mà thôi.
Tuy nhiên, khoan hãy bàn tới cách tối ưu nhất, chúng ta hãy xuất phát từ những idea sơ khai nhất, chắc chắn việc đầu tiên cần làm là đếm số lần xuất hiện của từng phần tử, sử dụng Map với key là từng phần tử trong mảng nums, còn value chính là biến đếm số lần xuất hiện với key tương ứng.
Sau khi đếm xong ta cần sắp xếp lại key theo số lần xuất hiện của chúng, và lấy k key có số lần xuất hiện nhiều nhất. Vậy là đã rõ, bài toán có tối ưu hay không phụ thuộc hoàn toàn vào cách chúng ta sắp xếp số lần xuất hiện của các key như thế nào.
Dưới đây sẽ là 3 solutions tương ứng cho 3 cách sắp xếp khác nhau.
2. Solution & Phân Tích
Ví dụ minh hoạ: nums = [1,3,1,1,2,2], k = 2;
Task đầu tiên có thể apply cho cả 3 cách như đã đề cập đó chính là việc ta sẽ dùng Map để đếm số lần xuất hiện của từng phần tử.

Space Complexity: O(n)
Time Complexity: O(n)
n: số phần tử của mảng.
2.1. Sort Map với Max Heap
Heap là 1 cấu trúc dữ liệu đặc biệt, các bạn có thể tham khảo thêm tại đây: Max Heap Wiki
Và với Max Heap, node root luôn chứa giá trị max, khi chúng ta thực hiện phép lấy max value ra khỏi heap, nó sẽ tự động tái cấu trúc lại heap với O(logn), và vì ta cần lấy ra k phần tử nên cần duyệt qua heap và get max value k lần, nên độ phức tạp sẽ là O(klogn)
Ta sẽ coi mỗi entry trong Map là 1 node, entry tương ứng với 1 cặp key value, ta sẽ so sánh các node dựa trên số lần xuất hiện của phần tử, hay dựa trên value của entry và sẽ xây dựng Max Heap dựa trên Map mà ta đã xây ở bước đầu. Độ phức tạp sẽ là O(nlogn) vì ta cần duyệt qua tất cả entry của Map với O(n) và thêm từng entry vào Max Heap với O(logn). Sau khi khởi tạo xong, ta được 1 Max Heap:

Ta có thể thấy node gốc có key là 1 và value là 3, tương ứng cho số lần xuất hiện của số 1 là 3 lần, và 3 cũng chính là giá trị Max trong Heap hiện tại.
Với k = 2, ta cần lấy ra 2 thằng có số lần xuất hiện nhiều nhất, lần lượt thực hiện:
1. Lấy ra node root (1 -> 3), từ đây ta lấy key chính là số 1 và thêm vào mảng kết quả để trả về, ta được mảng [1]. Lúc này Max Heap còn lại:

2. Lấy ra node root (2 -> 2), từ đây lấy key chính là số 2 và thêm vào mảng kết quả trả về, ta được mảng [1, 2]. Lúc này Max Meap chỉ còn lại 1 node (3 -> 1)
Ta dừng lại vì đã đủ k = 2 phần tử, và trả về mảng tìm được là [1,2] có ý nghĩa số 1 và 2 chính là 2 số có số lần xuất hiện nhiều nhất trong mảng nums = [1,3,1,1,2,2];
Space Complexity: O(n + n) = O(2n) = O(n) (dùng Map + Heap nên phải cộng 2 n lại)
Time Complexity: O(n + nlogn + klogn) = Max(O(2n), O(nlogn), O(klogn)) = O(nlogn) (duyệt map tốn O(n), duyệt qua n entry và tạo heap tốn O(nlogn), duyệt qua k phần tử + remove root tốn O(klogn))
n: số phần tử của mảng.
k: số phần tử xuất hiện nhiều nhất.
2.2. Sort Map với TreeMap
Đây là 1 cấu trúc dữ liệu đặc biệt trong Java. TreeMap về cơ bản cũng giống Map nhưng nó duy trì thứ tự tăng dần hoặc giảm dần theo Key, lưu ý là theo Key chứ không phải theo Value nha ae 😀 Và đằng sau Tree Map sẽ sử dụng 1 cấu trúc dữ liệu đặc biệt có tên là "Red-Black Tree" hay cây đỏ đen, các bạn có thể tham khảo thêm tại: Red-Black Tree - Wiki
Vì ta đã tạo sẵn 1 map tạm gọi là count để đếm với Key là giá trị phần tử còn Value là số lần xuất hiện của nó. Vậy câu hỏi đặt ra là nếu sử dụng thêm 1 Tree Map nữa, thì ta sẽ sắp xếp Map count đã có theo value của nó như thế nào?
Câu trả lời thật đơn giản, ta chỉ cần khởi tạo 1 Tree Map với key chính là value của Map count trước đó, chính là số lần xuất hiện của các phần tử, còn value chính là list các key của Map count có cùng số lần xuất hiện. Nói chung là ta sẽ chuyển đổi từ Map thông thường sang Tree Map bằng việc đảo ngược key và value. Độ phức tạp của việc khởi tạo sẽ là O(nlogn), do cần duyệt qua tất cả entry của Map count với O(n) và add từng entry vào Tree Map với O(logn).
Bằng cách làm này, khi khởi tạo Tree Map, mặc định nó sẽ sắp xếp các key (số lần xuất hiện của từng phần tử) theo thứ tự tăng dần, ta sẽ lấy lần lượt lấy ra node có key lớn nhất trong Map và thêm vào mảng kết quả, mỗi lần như vậy Tree Map sẽ tốn O(logn) để tái cấu trúc lại, và sau k lần như thế độ phức tạp sẽ là O(klogn).
Map ban đầu:


Ta có thể thấy node có giá trị lớn nhất là 3 -> [1], tương ứng với việc số 1 xuất hiện 3 lần.
Với k = 2, ta cần lấy ra 2 thằng có số lần xuất hiện nhiều nhất, hay 2 key có giá trị lớn nhất, lần lượt thực hiện:
1. Lấy ra node có giá trị lớn nhất (gọi phương thức pollLastEntry trong Java), từ đây ta lấy value chính là số 1 và thêm vào mảng kết quả để trả về, ta được mảng [1]. Lúc này Tree Map còn lại:

2. Lấy ra node (2 -> [2]), từ đây lấy value chính là số 2 và thêm vào mảng kết quả trả về, ta được mảng [1, 2]. Lúc này Tree Map chỉ còn lại node (1 -> [3])
Ta dừng lại vì đã đủ k = 2 phần tử, và trả về mảng tìm được là [1,2] có ý nghĩa số 1 và 2 chính là 2 số có số lần xuất hiện nhiều nhất trong mảng nums = [1,3,1,1,2,2];
Space Complexity: O(n + n) = O(2n) = O(n) (dùng 2 Map nên phải cộng 2 n lại)
Time Complexity: O(n + nlogn + klogn) = Max(O(2n), O(nlogn), O(klogn)) = O(nlogn) (duyệt map tốn O(n), duyệt qua n entry và tạo Tree Map tốn O(nlogn), duyệt qua k phần tử + remove max node tốn O(klogn))
n: số phần tử của mảng.
k: số phần tử xuất hiện nhiều nhất.
2.3. Sort Map với Bucket Sort
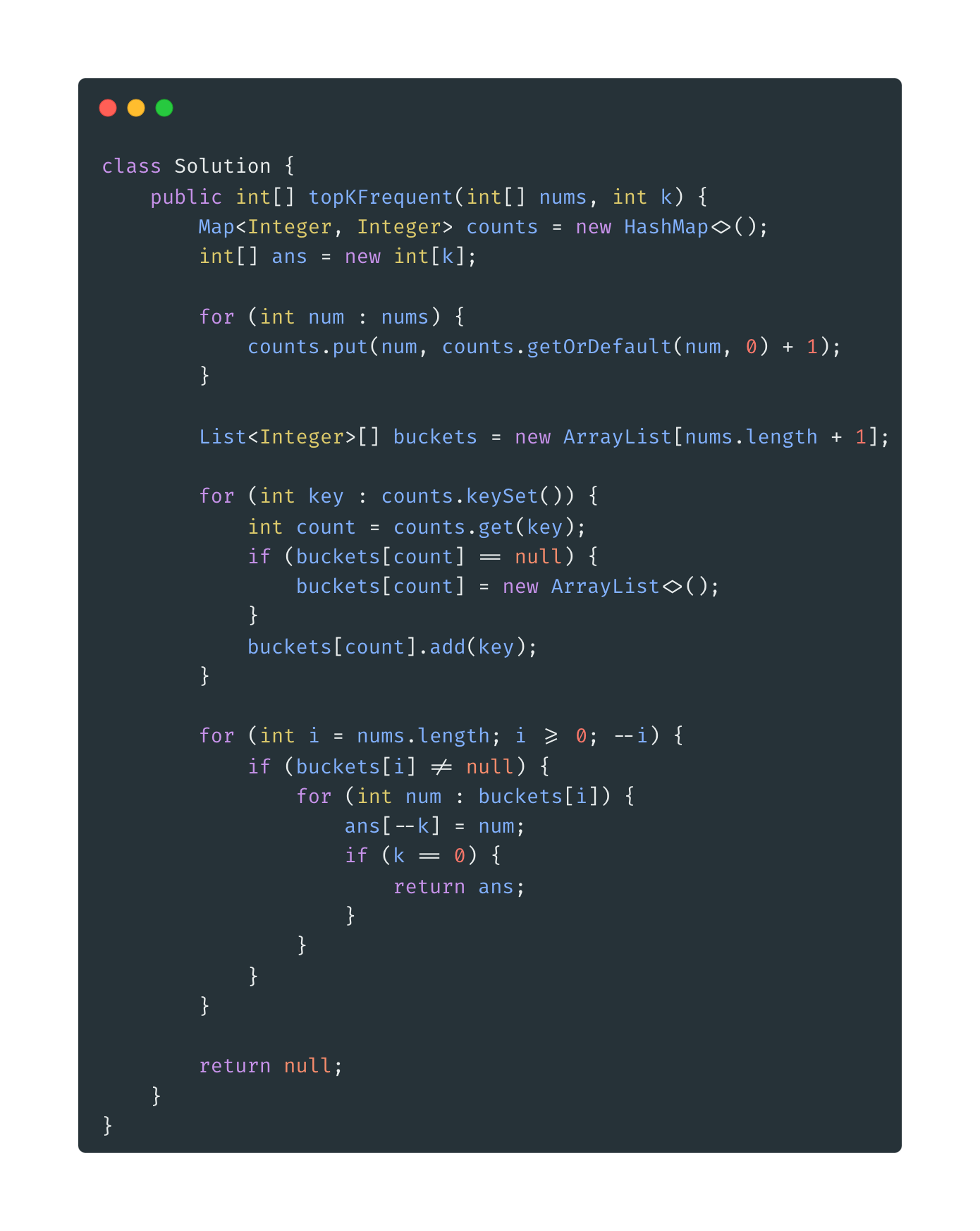
Đây là một trong những cách sắp xếp tối ưu nhất, khi sử dụng idea của bucket sort - các bạn có thể tham khảo thêm tại đây: Bucket-Sort-Wiki . Và độ phức tạp thời gian của nó sẽ tối ưu hơn O(nlogn) nhưng cũng cần phải thỏa một số điều kiện nhất định nên nó không được áp dụng rộng rãi cho mọi bài toán như Quick Sort.
Từ Map đếm ban đầu, ta sẽ tạo 1 mảng bucket với chiều dài bằng chiều dài của mảng nums + 1 = n + 1, vì mỗi index sẽ tương ứng với 1 bucket và sẽ đại diện cho số lần xuất hiện của các phần tử, ví dụ: phần tử tại index 1 sẽ xuất hiện 1 lần,.. Vì số lần xuất hiện max của 1 phần tử sẽ bằng với chiều dài của mảng nums là n, nên đó chính là lí do vì sao ta cần khởi tạo mảng bucket với chiều dài bằng n + 1.
Và vì sẽ có nhiều phần tử sẽ có cùng số lần xuất hiện, và do đó sẽ có cùng index, nên ta cần tạo mảng 2 chiều cho bucket, và trong Java thì ta chỉ cần tạo mảng với kiểu list để có thể dễ dàng thao tác, mục đích là để có thể lưu hết tất cả phần tử có cùng index đó.
Từ Map ban đầu:
Ta sẽ tạo 1 mảng bucket kiểu list với chiều dài là 7. Sau đó, ta sẽ đi qua từng entry của Map, entry đầu tiên là (1 -> 3) tương ứng số 1 xuất hiện 3 lần, ta sẽ bỏ nó vào bucket có index là 3:

Tiếp theo là entry (3 -> 1) tương ứng số 3 xuất hiện 1 lần, ta sẽ bỏ nó vào bucket có index là 1:

Cuối cùng là entry (2 -> 2) tương ứng số 2 xuất hiện 2 lần, ta sẽ bỏ nó vào bucket có index là 2:

Sau khi có được mảng bucket như trên, vì đề bài yêu cầu ta tìm k số xuất hiện nhiều nhất nên ta chỉ cần đi từ cuối mảng, là từ index cuối cùng là 7 đi ngược về index đầu tiên là 0, và get ra tương ứng từng value với từng index cho tới khi đủ k phần tử là được.
Trong trường hợp k = 2, thì có thể thấy index tại 3 và 2, tương ứng số lần xuất hiện là 3 và 2 có hai số đáp ứng lần lượt là 1 và 2, như vậy ta có thể kết luận 2 số có số lần xuất hiện nhiều nhất chính là 1 và 2, ta thêm 1 và 2 vào mảng kết quả và trả về.
Space Complexity: O(n + n) = O(2n) = O(n) (dùng 2 Map nên phải cộng 2 n lại)
Time Complexity: O(n + n + k) = O(n) (duyệt map tốn O(n), duyệt qua n entry và tạo bucket array tốn O(n), duyệt qua k phần tử và tạo mảng kết quả tốn O(k))
n: số phần tử của mảng.
k: số phần tử xuất hiện nhiều nhất.
3. Code
3.1. Sort Map với Max Heap

3.2. Sort Map với TreeMap

3.3. Sort Map với Bucket Sort








{kind=link}